My apologies for the lateness of this article... holiday seasons have that effect.
This month, I plan to tackle two subjects at once, assembly language programming, and the line-of-sight algorithm used in my CRPG.
Of all the various computer languages, none invokes greater fear and trepidation than assembly language. A brief glimpse of it is usually seen in a computer science degree path, but no more. Few software jobs involve assembly, beyond trying to interpret the stack contents of your latest thrown C/C++ error. Only ancient engineers speak wistfully of the days of pushing registers instead of mucking about with all this object-oriented nonsense. It's the Kabala of computer linguistics.
Here's the straight truth: assembly is not hard to understand, nor hard to write. Anyone can learn it, if they choose to do so.
So where does this nefarious reputation come from? Well, it's because while it's simple in design, it can be very pedantic in form. Unlike other languages, where you have abstract commands to handle a lot of common tasks, assembly has little or none. Maintaining assembly code is also a difficult task, especially when poorly documented.
What about macros, you ask? These allow you to replicate large blocks of code with a single line. From a coder's standpoint, this makes the code shorter and easier to understand. But the truth is, assembly works better simply because you AVOID heavy abstraction. And on the TI-99/4a, you rarely have the memory to burn on replication of code.
Assembly is fast, but efficiency is still necessary for optimum processing. It's very easy to write a poor assembly program. Unlike high-level languages, with focus on easier readability and logical flow from the human perspective, assembly is all about thinking how the computer does. The more you recognize what it is REALLY doing, at the lowest level, the better written it is for efficiency. This also means that optimal assembly can sometimes become a real train wreck of code.
Three easy things to remember about assembly language programming, which I cover in detail below:
Variables are, naturally, one of the principal elements of any computer language. In TI BASIC and Extended BASIC, you have two types: numeric and string. In C, you have multiple types, including integers, floats, characters, and so forth. You also have pointers, which, instead of being a value, are an address to a specific place in memory.
In assembly, all you have is memory, measured in words. And because of how the symbolic table works, everything can be either a value or a reference to a memory address. There are no types in assembly, just numbers. (Integers, to be specific.) Floating points are represented on the TI as 8-byte segments of memory, which are manipulated by the built-in low-level routines. (You could work with them directly, if you wanted to.) Strings are just raw data, whether you use a delimiter to mark where they end or begin them with a length value is up to you. And nothing throws a "type error"; because everything is represented the same way. What you have happen instead is some very oddball errors. (Try branching to some text data and you'll see what I mean.)
On the TI-99/4a, the word size is 16-bits, or 2 bytes of memory. This is big enough to store a value from 0-65535, or -32768 to 32767, depending on whether or not you want negative numbers. If you need larger integers, you can use an extra word, using the carry bit to determine when a value "spills over" into the second word.
One particular problem to watch out for with TMS9900 programming is the 15-bit address issue. The TI-99/4a has a split address line; most access is actually 15-bit, addressed in words. The instruction set has two sets of instructions for various operations, word and byte. MOV, for example, copies whole words at even-numbered addresses to other even-numbered addresses. If you want to copy a single byte or access an odd-numbered address, you must use MOVB. Another complication is indirect indexing with a register counts in bytes, not words. That means your index count is in bytes, whether or not you're using word or byte instructions.
In assembly, most of your work is done with registers. They serve as methods to pass values between parts of code, store context switch information and subprogram return addresses, and a general workspace to do your calculations. Registers can be used as values or as pointers, as indexes for a data array, and can also be auto-incremented in steps of 1 or 2, all in a single line of assembly code.
On most computers, the registers are "local" to the CPU, that is, they're basically built into it so that it can access the data in them at maximum speed. The TMS9900 processor that drives the TI-99/4a has a different approach. The workspace for the registers is located in external memory, and the CPU only has a pointer to it. This means our registers aren't quite as fast, since they have to traverse the data bus, but we can switch context (that is, switch to a whole new set of registers) in an instant. Other systems, like the 8086 PC, have to dump the register contents on the hardware stack before switching contexts. (You can gain a bit more speed with TI's registers by placing them in the scratch-pad RAM, located at address >8300.)
One particular advantage the TI has is that because the registers are located in external RAM, most of the instructions can do memory-to-memory operations. For example, you can use the A instruction to add two memory areas without involving a single register. The 8086 PC, by contrast, has to restrict most calculations to the registers. That means you spend a lot of time moving values into and out of them. The only operations in the TMS9900 that are restricted to registers are commands that use immediate values.
To sum up, always keep in mind that the labels are there for your convenience, not the computer's. And that they don't represent variables, exactly, but spaces of memory. Adjust your thought process; it will help find new and better solutions to coding problems in assembly.
Unlike compiled languages, assembly language has very simple control structures. Operations cause status bits to set and reset, based on the result of any instruction. Different assembly languages have different types of status bits, and different combinations make up the general set of results, such as "equals", "not equals", "greater than", "greater than or equal to", and so forth.
A series of "jump" commands exist in assembly to change the address pointer based on the values of those status bits. The most frequently used is the equality bit, for checking if something is equal, or not equal. When checking for greater than/less than, there are also different commands for signed or unsigned numbers. (If you know your two's compliment binary, you know that negative numbers look like really BIG positives to the wrong instruction.)
I often use the term "atomic programming" to describe assembly language, and it comes into sharp focus with control structures. What I mean when I say it is that your instruction set consists of very simple and direct commands, which can be thought of as the protons, neutrons and electrons of an atom. By themselves they don't do much, but in combination, very complicated objects, or code, can be made from them. Modern programming in heavily abstracted languages, such as Java, are more "molecular" in scope, with the classes, interfaces, and objects interacting with one another in an abstract space, sometimes in unpredictable ways.
In assembly, you still have a classic IF/THEN structure. In TMS9900 assembly, it may look like this:
C R3,R4
JEQ L200
These two lines compare the word values in registers 3 and 4. If they are equal, it changes the instruction pointer to point at the address symbolically represented by the label L200.
150 IF R3=R4 THEN 200Not so bad, is it? However, converting a BASIC statement like this is a bit more complicated:
150 IF (R3=1)*(R4=2) THEN 200In TI BASIC, any calculation put within parenthesis returns a 0 if the interior statement is false, and a -1 if the statement is true. If the result of any calculation is 0, the statement is false, otherwise true. In TI Extended BASIC, you could write it as:
150 IF R3=1 AND R4=2 THEN 200In assembly language, it's a bit more complicated. Each condition must be checked individually:
CI R3,1
JEQ S2
JMP S3
S2 CI R4,2
JEQ L200
S3 ...(false condition code)
.
L200 ...(true condition code)
This is only one way of doing it. Here's another way:
CI R3,1
JNE S2
CI R4,2
JNE S2
L200 ...(true condition code)
S2 ...(false condition code)
Aside from saving a line and a few bytes, this version also saves us a few labels.
So how about the FOR/NEXT control structure? This can be seen in TI BASIC as follows:
100 FOR I=1 to 10 110 R1=R1+2 120 NEXT IIn assembly, you could do this as follows:
CLR R0
F1 INCT R1
INC R0
CI R0,9
JNE F1
One interesting side point is that anytime an instruction sets a register or memory word/byte to zero, the equality bit is set. This is a handy tool by which you can build a natural stop on a looping set of code which decrements a counter value. PC 8086 assembly uses the C register exclusively for looping, but on the TI any of them will do.
LI R0,10
F1 INCT R1
DEC R0
JNE F1
Aside from saving a line, it also saves us a redundant comparison. Never have more comparisons than what you absolutely need in a looping control structure!
Probably the most difficult control structure to replicate in assembly is the switch-case statement. In high-level languages, this provides a quick and simple method to have the program perform a variety of different tasks, based on the value of a single variable. Switch statements also offer the flexibility of a "default" parameter, the option chosen for anything not otherwise specified. BASIC doesn't offer this.
There's a couple different ways to do a switch-case statement in assembly. One way is more memory-consumptive, but easier on the programmer to write and edit. The second way requires no data, but can easily lead to some nasty inexplicable errors.
Let's take a simple switch-case statement, as follows:
switch (R1)
{
case 0: ...(first action)
case 1: ...(second action)
case 2: ...(third action)
case default: ...(default action)
}
The above is the structure you may see in C++ or Java. Here's how it would look in TI BASIC:
110 ON R1 GOTO 500,600,700 . 500 ...(first action) . 600 ...(second action) . 700 ...(third action)Unfortunately, TI BASIC doesn't have an option to default the value, the programmer has to put some kind of check in for any errant values before reaching the ON GOTO statement.
CASE0 ... (first action)
CASE1 ... (second action)
CASE2 ... (second action)
CASEDF ... (default action)
.
SWTC DATA 3,CASE0,CASE1,CASE2,CASEDF
.
C @SWTC,R1
JLE SW1
LI R1,3
SW1 SLA R1,1
MOV @SWTC(R1),R0
B *R0
Unlike your average C++/Java compiler, assembly does NOT do the job of determining how many potential cases there are in a switch-case statement. The programmer must code in a check. As you can see from above, I stored the number of potential options as the first word in the data segment, followed by the addresses. I also had it check for any values outside the range, and if there were any, it sets the value to 3, the default case.
CASE0 ... (first action)
CASE1 ... (second action)
CASE2 ... (second action)
CASEDF ... (default action)
.
LI R0,SWBASE
CI R1,3
JLE SW1
LI R1,3
SW1 SLA R1,2
A R1,R0
B *R0
SWBASE B @CASE0
B @CASE1
B @CASE2
B @CASEDF
Instead of using a data statement, a symbolic address is used as a "base" address for the branching statements to the different cases. Since each branch command occupies 4 bytes of memory, we can multiply the register by 4 (using the SLA command for speed and efficiency) and just add it to the base address and branch to it. You could use a similar technique to build an ON GOSUB, using BL instead.
We've all heard of the box. Often, we're told to think outside of it. Usually this is just something your manager says to sound really clever and insightful, and he really has no clue what he means.
In simple terms, the box is a phrase referring to boundaries. For example, in TI BASIC, you only have access to redefine characters 32-159. This is a boundary, you can't really break it. You also only have access to a single video mode in TI-BASIC. You can't access the sound voices independently of each other, except for the first and noise generator, because of the way that the SOUND subprogram is written.
In assembly, you're not exactly "outside the box". That's because there IS NO BOX. This is both an advantage and a disadvantage.
The advantage is you have nearly total access to everything on the system. There are some routines provided to you, such as the utility vectors (VSBW, DSRLNK, GPLLNK and so forth), but even these can be overwritten. If you REALLY wanted to, you could go down to controlling the disk drive directly, stopping and starting the spins.
There are some boundaries, but they are dependent upon how the hardware is structured, and are out of your control no matter what language you use. For example, the video chip's refresh sync is completely controlled by hardware, you can't do any of the artifact color tricks other 8-bit computers like the Atari and Commodore 64 were known for, because the CPU is not involved in generating the video at all.
The disadvantage is, well, just that, no box. You have to write everything yourself. Do you need to display a text message on the screen? Well, there's no DISPLAY AT, you have to provide that. And after writing that, what if you want to display a register's value on screen? Have to write a routine to figure out how to turn a 2-byte integer into a string of text yourself. And yes, you have to write your own INPUT command too. That cursor doesn't blink itself, you know.
Having no box can be very scary and intimidating to a lot of programmers. And the overhead from just writing basic functionality for a program can be a headache. Most assembly programmers build up a personal "library" of basic routines, as described above, so they can just stick them in when needed.
The great thing about no box is that every program has complete room to take everything that the computer has to offer. And for any advanced program, this is an absolute necessity.
All this begs the question, naturally, of "If assembly's so great, why don't they use it today?"
Well, the principal reason is that assembly language programs are only manageable in small sizes. The sheer weight of code to perform even simple operations is staggering. As a single programmer, I'm finding that my CRPG is a project of sufficient complexity to be very taxing to even conceive of as a whole.
Secondly, as compiler technology has improved, the need for direct assembly has diminished. C and C++, at least the non .NET versions, compile directly into machine code, and are very efficient at it. They even have their own optimization algorithms to make the abstract high-level code conform better to the machine's expectations.
Finally, the large amounts of memory available both in storage and in RAM have made the need for minute metrics in coding impractical. An extra instruction or two or even a couple macros just don't have enough impact on program efficiency to make it worthwhile to go to the assembly level. The PC game Doom, for example, was written entirely in C code, using only a few assembly routines to push data to the video card slightly quicker. It's not impossible to write a modern application in assembly (The first Rollercoaster Tycoon game was), it's just a lot of extra work with little purpose.
However, my own experience with modern language platforms has been that the amount of abstraction is starting to get very heavy. Languages like Java and C# are very compiler-dependent because there are literally thousands of classes, more than any human being could remember. Programmers must rely on the compiler to write a lot of the code for them just by locating classes needed for particular tasks. This is NOT fun programming.
Also, if you actually look at assembly code running through modern CPU's, it's disturbing. It's just massively long lists of subroutine calls; you're hard pressed to find a single statement that's actually DOING something. Computer users complain of "bloat" in modern software suites, I'm more concerned with "clutter" in the code stream.
However, assembly is still a useful thing to learn about. I know this from debugging C++ code. No matter what language you learn or use, in the end, it all becomes machine code eventually, so knowing something about how things work inside the black box can be an invaluable experience.
Well, after a long and dry explanation of assembly, I'm certain you're asking, where does this come in to CRPG design?
 Well, some tasks in a CRPG are pretty simple to execute, and can be done in any language. Some, though, are very complicated, and require a great deal of computational power. The line-of-sight algorithm is definitely in the latter category.
Well, some tasks in a CRPG are pretty simple to execute, and can be done in any language. Some, though, are very complicated, and require a great deal of computational power. The line-of-sight algorithm is definitely in the latter category.
So, the first question is, why have a line-of-sight algorithm? Because it lets you restrict what the player can actually see on-screen. Mazes are certainly not fun to solve if you can see the whole thing at once. By having "blocking" tiles, such as forests or mountains, you can create a bit of mystery in an otherwise unremarkable landscape. Is there something beyond that mountain range? Are there hidden secrets in that old wood? Some games use a mapping technique to block off areas, instead of an algorithm. This is great, if you have the memory to burn on storing map data for it. An algorithm is a much smoother and elegant way to solve the problem, and is easily done on a classic microcomputer like the TI-99/4a.
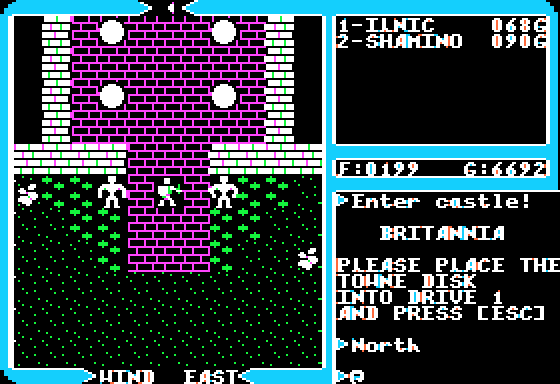 The first CRPG I saw with an LOS algorithm was Ultima III. Or more specifically, Ultima: Exodus on the classic Nintendo. I initially didn't know what to make of it, the screen looked jagged and strange. (The starting areas in the game are located inside a spiral of walls, blocking most of your sight.) After I understood what I was seeing, it was a very interesting effect.
The first CRPG I saw with an LOS algorithm was Ultima III. Or more specifically, Ultima: Exodus on the classic Nintendo. I initially didn't know what to make of it, the screen looked jagged and strange. (The starting areas in the game are located inside a spiral of walls, blocking most of your sight.) After I understood what I was seeing, it was a very interesting effect.
One problem, though, was that the LOS algorithm went too far. A single obstructing block in front of you blocked off 25% of the screen. Navigation in the game was difficult, and a lot of the map was hidden from view. Turning a corner and running into something you weren't expecting is not fun, to say the least.
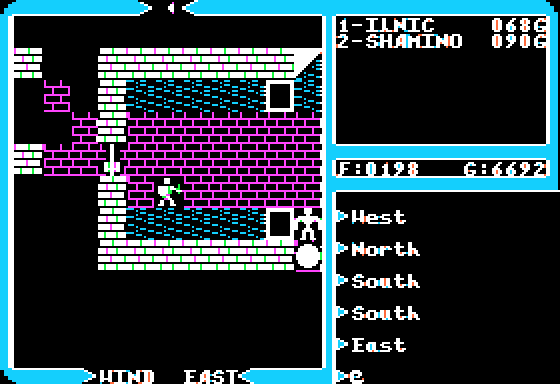 In Ultima IV, a change was made to the LOS algorithm, making it more permissible. Unless you're right next to a block, 25% isn't blocked off, instead, just a straight cardinal line is. You can see around blocks and corners that make logical sense to see around. There's some oddities, but you have to search for them, and they don't inhibit gameplay at all.. The PC version has a slightly different routine from the Apple II/C64 versions, but it is comparable in results.
In Ultima IV, a change was made to the LOS algorithm, making it more permissible. Unless you're right next to a block, 25% isn't blocked off, instead, just a straight cardinal line is. You can see around blocks and corners that make logical sense to see around. There's some oddities, but you have to search for them, and they don't inhibit gameplay at all.. The PC version has a slightly different routine from the Apple II/C64 versions, but it is comparable in results.
I studied the effects in both games, but I couldn't discern the algorithm used to create it. I could map out the results by studying screen shots from the games, but that didn't lead anywhere. I thought they were using some kind of mapping scheme to block out elements, but every time I thought I had it, a screen shot came up that broke the model. Finally, I used an Apple II emulator that allowed you to actually view the 6502 code as it ran line-by-line, and extracted the routine out of Ultima IV. (You can view the raw 6502 code here.)
What I discovered was, there was no mapping scheme. Just a lot of grinding and processing going on. Every individual square on the screen is individually calculated, a task beyond anything you could ever do in TI BASIC, or even Extended BASIC.
The algorithm is, in fact, very simple:
And that's a wrap. Next article, I'll cover video, graphics and animation.